Experts Find A Way To Learn What You're Typing During Video Calls

A new attack framework aims to infer keystrokes typed by a target user at the opposite end of a video conference call by simply leveraging the video feed to correlate observable body movements to the text being typed.
The research was undertaken by Mohd Sabra, and Murtuza Jadliwala from the University of Texas at San Antonio and Anindya Maiti from the University of Oklahoma, who say the attack can be extended beyond live video feeds to those streamed on YouTube and Twitch as long as a webcam's field-of-view captures the target user's visible upper body movements.
"With the recent ubiquity of video capturing hardware embedded in many consumer electronics, such as smartphones, tablets, and laptops, the threat of information leakage through visual channel[s] has amplified," the researchers said. "The adversary's goal is to utilize the observable upper body movements across all the recorded frames to infer the private text typed by the target."

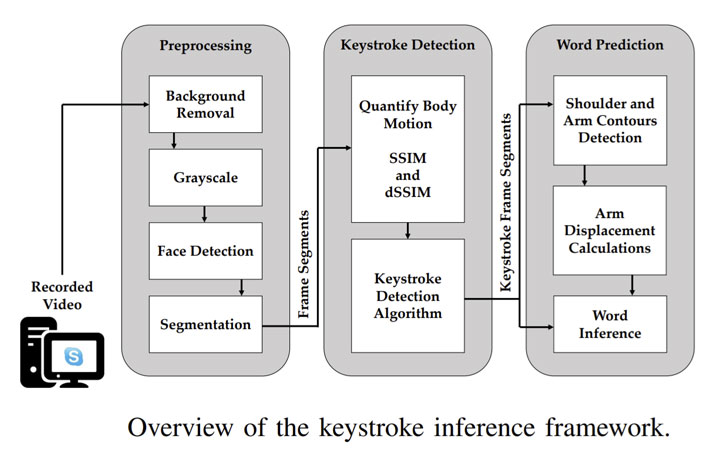
To achieve this, the recorded video is fed into a video-based keystroke inference framework that goes through three stages —
- Pre-processing, where the background is removed, the video is converted to grayscale, followed by segmenting the left and right arm regions with respect to the individual's face detected via a model dubbed FaceBoxes
- Keystroke detection, which retrieves the segmented arm frames to compute the structural similarity index measure (SSIM) with the goal of quantifying body movements between consecutive frames in each of the left and right side video segments and identify potential frames where keystrokes happened
- Word prediction, where the keystroke frame segments are used to detect motion features before and after each detected keystroke, using them to infer specific words by utilizing a dictionary-based prediction algorithm
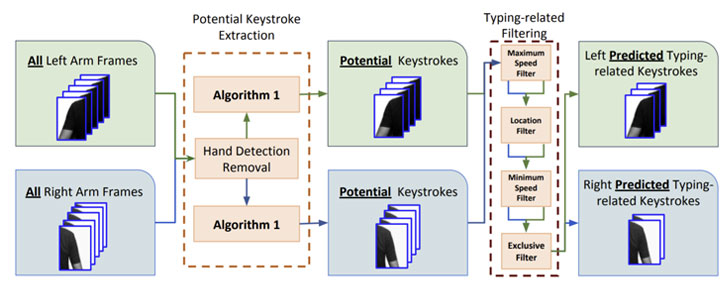
In other words, from the pool of detected keystrokes, words are inferred by making use of the number of keystrokes detected for a word as well as the magnitude and direction of arm displacement that occurs between consecutive keystrokes of the word.
This displacement is measured using a computer vision technique called Sparse optical flow that's used to track shoulder and arm movements across chronological keystroke frames.
Additionally, a template for "inter-keystroke directions on the standard QWERTY keyboard" is also charted to denote the "ideal directions a typer's hand should follow" using a mix of left and right hands.
The word prediction algorithm, then, searches for most likely words that match the order and number of left and right-handed keystrokes and the direction of arm displacements with the template inter-keystroke directions.
The researchers said they tested the framework with 20 participants (9 females and 11 males) in a controlled scenario, employing a mix of hunt-and-peck and touch typing methods, aside from testing the inference algorithm against different backgrounds, webcam models, clothing (particularly the sleeve design), keyboards, and even various video-calling software such as Zoom, Hangouts, and Skype.
The findings showed that hunt-and-peck typers and those wearing sleeveless clothes were more susceptible to word inference attacks, as were users of Logitech webcams, resulting in improved word recovery than those who used external webcams from Anivia.
The tests were repeated again with 10 more participants (3 females and 7 males), this time in an experimental home setup, successfully inferring 91.1% of the username, 95.6% of the email addresses, and 66.7% of the websites typed by participants, but only 18.9% of the passwords and 21.1% of the English words typed by them.
"One of the reasons our accuracy is worse than the In-Lab setting is because the reference dictionary's rank sorting is based on word-usage frequency in English language sentences, not based on random words produced by people," Sabra, Maiti, and Jadliwala note.
Stating that blurring, pixelation, and frame skipping can be an effective mitigation ploy, the researchers said the video data can be combined with audio data from the call to further improve keystroke detection.
"Due to recent world events, video calls have become the new norm for both personal and professional remote communication," the researchers highlight. "However, if a participant in a video call is not careful, he/she can reveal his/her private information to others in the call. Our relatively high keystroke inference accuracies under commonly occurring and realistic settings highlight the need for awareness and countermeasures against such attacks."
The findings are expected to be presented later today at the Network and Distributed System Security Symposium (NDSS).
Source: feedproxy.google.com
 Reviewed by Anonymous
on
5:44 AM
Rating:
Reviewed by Anonymous
on
5:44 AM
Rating:




